

{kind=link}
La plateforme d’orchestration open source Apache Hop (Hop en abrégé) a été publiée dans sa première version majeure. Le projet, qui a débuté en 2019, est en phase d’incubation à la Fondation Apache depuis septembre 2020. Les scientifiques des données et les développeurs peuvent l’utiliser pour créer et modifier des flux de travail et des pipelines dans un environnement de développement visuel sur Windows, macOS et Linux. En outre, il existe également une version pour navigateur (Hop Web). Avec l’ensemble des runtimes, projets et environnements portables ainsi que le contrôle de version intégré, les options de test et d’autres fonctions, les équipes devraient être en mesure de contrôler et de gérer l’ensemble du cycle de vie de leurs projets à l’aide de Hop.
Le visuel d’abord, le code ensuite (ou complètement dispensable)
Selon les responsables du projet, toute personne travaillant avec Hop n’a besoin que de peu ou pas de connaissances en programmation, car toutes les tâches telles que la conception, l’exécution, les tests, le débogage et l’exploitation des flux de données et des pipelines doivent être possibles de manière purement visuelle. Selon l’annonce faite sur le blog d’Apache, toutes les fonctions sont accessibles via l’interface graphique d’Hop, ce qui permet aux développeurs ayant une expérience de la programmation de travailler également avec des lignes de commande.
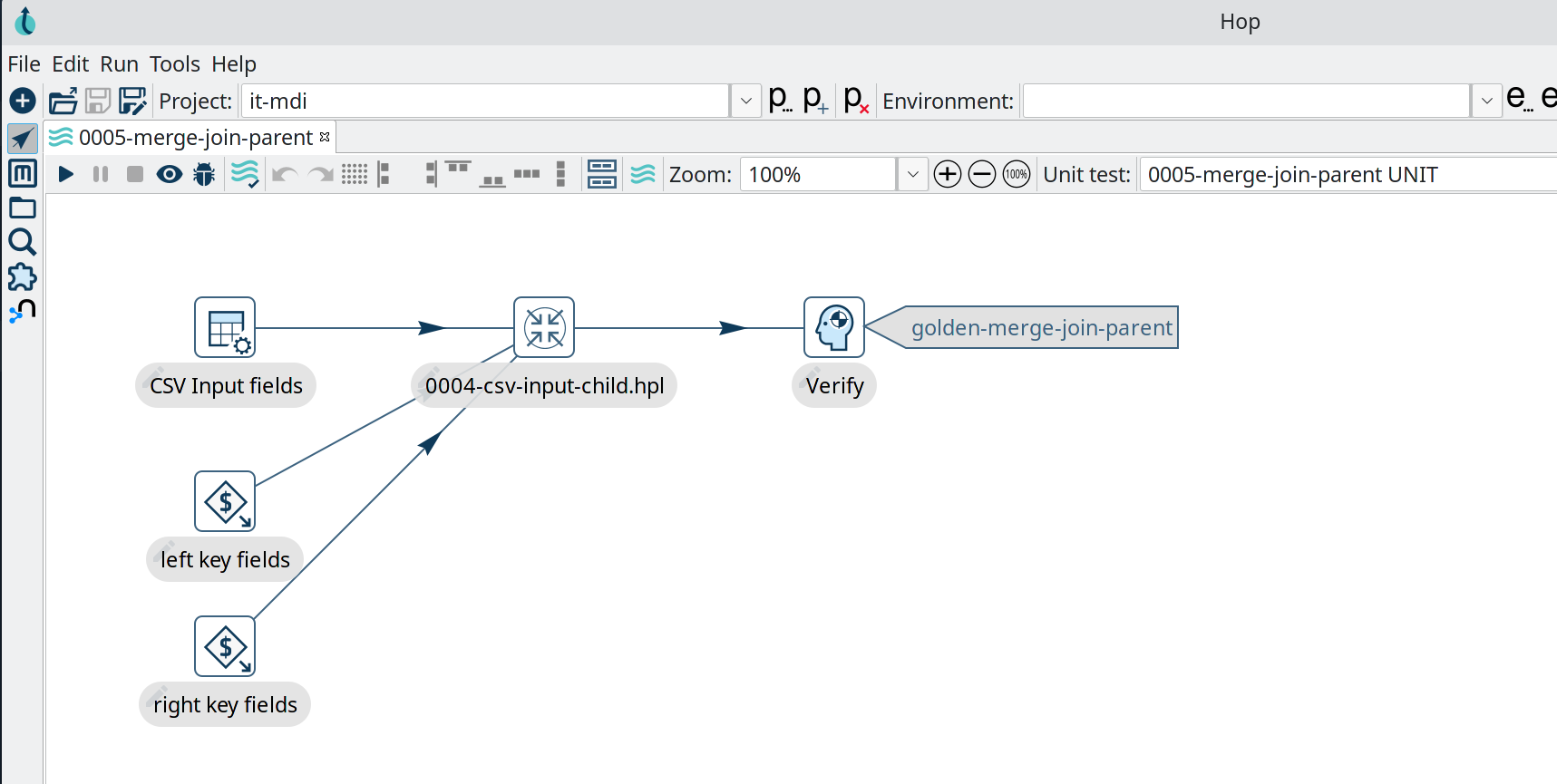
(Image : Fondation Apache)
Moteur minimaliste pour les appareils IoT et le streaming de données
Hop est un fork de la plateforme d’intégration de données Kettle (Pentaho Data Integration en version 8.2.0.7), mais selon les éditeurs, il n’est « pas destiné à être un fork hostile », mais plutôt un projet complémentaire visant à faire progresser de manière expérimentale les possibilités d’intégration de données. En séparant les deux projets, il y a maintenant une division claire entre une plateforme stable (Kettle) et le nouveau terrain de jeu pour tester des idées et des innovations (Hop), selon les responsables du projet.
Ce qui distingue essentiellement Hop de Kettle, c’est la réduction à un noyau de fonctions de base ; l’équipe a externalisé tout le reste, de l’architecture du moteur à la zone de branchement. Selon l’article de blog sur la page du projet Apache, l’objectif est que Hop puisse traiter des données provenant de dispositifs IoT de l’ordre du pétaoctet pour des scénarios de streaming, de batching ou de données hybrides.
Lire aussi

Selon les éditeurs, lors de la séparation avec Kettle, « aucune pierre n’a été négligée » : Hop a mis à jour toutes les dépendances, supprimé ou réécrit certaines parties du code et reconstruit le moteur Hop. Globalement, l’accent est mis sur un concept de plug-in modulaire, de sorte que le moteur prend en charge plus de 400 plug-ins et un total de 20 types de plug-ins différents.
Séparation stricte entre les métadonnées et la configuration
Outre l’accent mis sur un moteur allégé avec des modules d’extension, la prise en charge de différents scénarios de déploiement constitue une autre caractéristique particulière. Via l’interface graphique hop ou, en option, l’outil en ligne de commande hop-conf, les utilisateurs peuvent définir l’environnement approprié pour chacun de leurs projets, en fonction de l’objectif d’utilisation tel que le développement, les tests ou le CI/CD (Continuous Integration/Continuous Delivery or Deployment). Il est facile de passer d’un environnement à l’autre grâce à un menu déroulant dans l’interface utilisateur graphique. Hop sépare strictement le code dans les métadonnées d’un projet du niveau de configuration (les fichiers de l’environnement de travail).
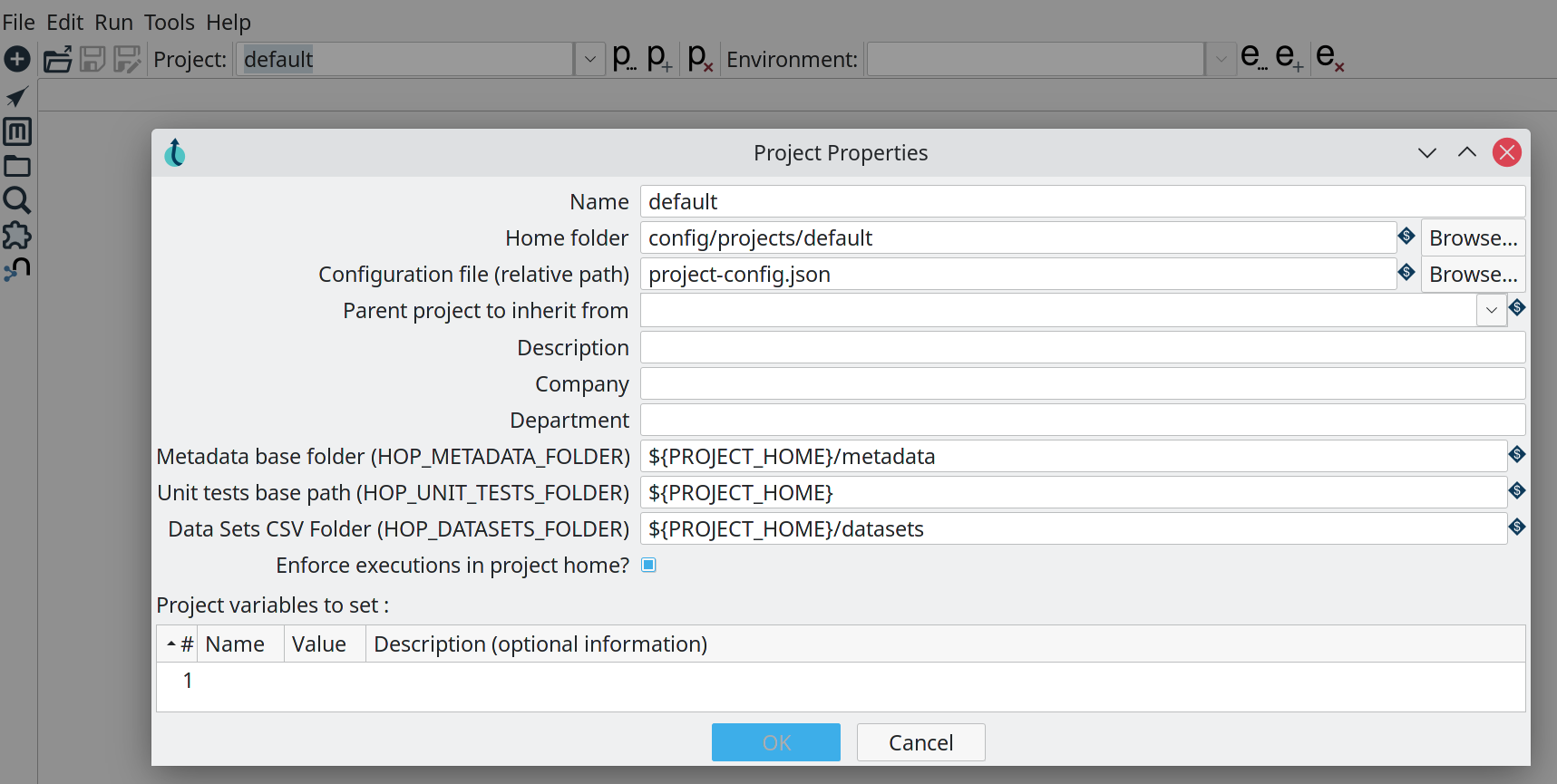
(Image : Fondation Apache)
Runtime portable pour un déploiement arbitraire
Selon l’équipe du projet, toute personne qui conçoit des flux de travail et des pipelines avec Hop en tant qu’ingénieur ou développeur de données peut les déployer partout. Outre le moteur local et natif, les pipelines créés dans l’interface graphique fonctionnent également sur Apache Spark, Apache Flink, Google Dataflow ou Apache Beam.
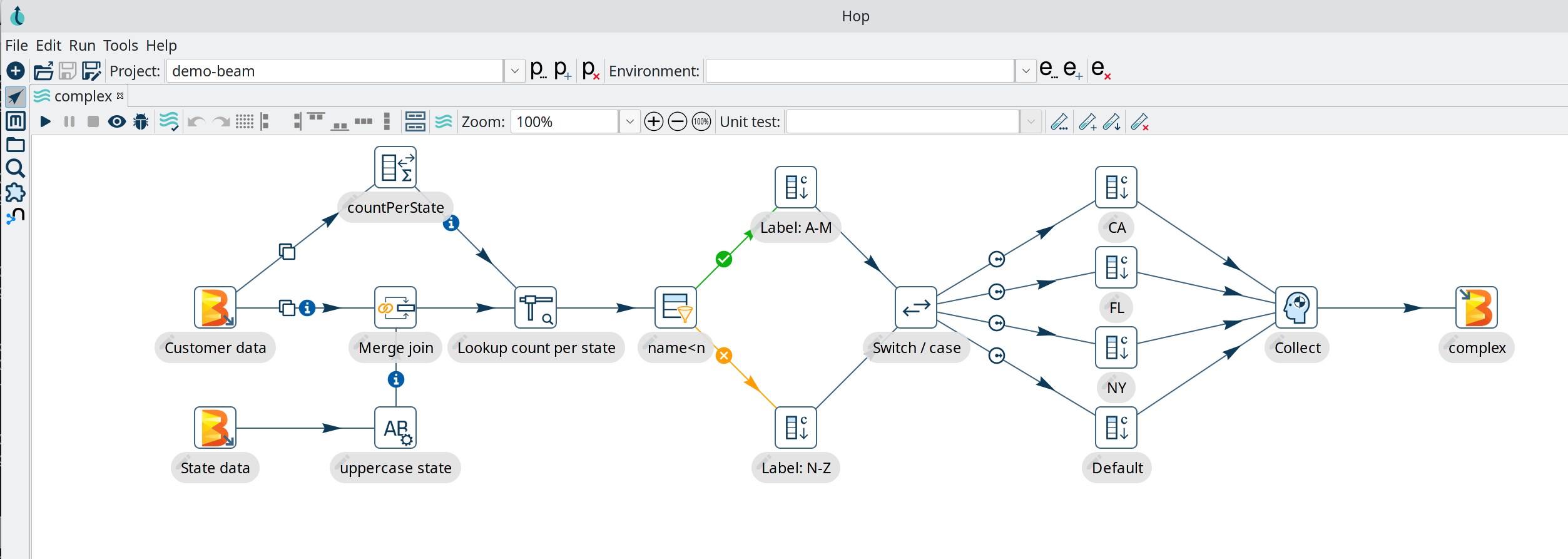
(Image : Fondation Apache)
Des tests unitaires pour tester les flux et les pipelines peuvent également être inclus dans l’interface graphique de Hop. Ils peuvent également être combinés à des tests d’intégration ou de régression plus complexes pour garantir que l’ensemble d’un projet ou d’un système se comporte comme prévu. La plateforme d’orchestration comprend une bibliothèque de tests unitaires, de régression et d’intégration qui ne cesse de s’enrichir et que les développeurs de Hop eux-mêmes disent avoir pu utiliser, entre autres, pour identifier et corriger des problèmes profondément ancrés dans la base de code de Kettle.
Feuille de route : Il y a encore quelque chose à venir
Un coup d’œil à la version actuelle de la feuille de route révèle ce qui est prévu : Le projet Hop prévoit la mise en place d’un marché de logiciels pour les plug-ins de tiers, des expressions de champs plugables dans le domaine des transformations et des actions, l’intégration avec Apache Airflow (à la fois dans Airflow lui-même et dans un nouveau moteur de workflow). La modularisation des plug-ins Apache Beam est prévue, ainsi qu’une plus grande unification des plug-ins Beam, et la conversion en cours de tous les plug-ins à la sérialisation XML générique devrait permettre aux développeurs de sérialiser JSON, YAML et des métadonnées similaires pour les pipelines et les flux de travail à l’avenir.
Apparemment, l’équipe Hop travaille également sur une nouvelle interface utilisateur graphique (GUI) pour l’exécution, la prévisualisation et le débogage des pipelines et des flux de travail. Un service de réseau pour la surveillance et la journalisation est probablement aussi prévu, qui devrait être capable d’accepter les métadonnées du fonctionnement continu des exécutions locales et distantes de Hop.
Ressources et autres références
Les personnes intéressées par les innovations actuelles et prévues dans Apache Hop peuvent consulter l’article de blog détaillé sur la sortie de la première version majeure. D’autres ressources sont disponibles dans la documentation, où les utilisateurs et les développeurs trouveront leurs propres guides. Des notes sur l’architecture et une section questions-réponses ainsi qu’une introduction pour les premiers pas avec la plate-forme complètent le paquet d’informations sur le site web du projet Hop à Apache. Les options de téléchargement y sont également indiquées.