

{kind=link}
Aleph Alpha met désormais à disposition la base de code de son modèle d’intelligence artificielle MAGMA en open source sur GitHub. L’équipe de la société allemande d’apprentissage automatique Aleph Alpha, basée à Heidelberg et Berlin, avait entraîné le modèle avec environ 200 milliards de paramètres en collaboration avec des chercheuses de l’université de Heidelberg. Le modèle est similaire à GPT-3, mais en tant que modèle vision-langage avec des capacités multimodales, il va au-delà du modèle linguistique et comprend potentiellement toute combinaison de texte et d’image, selon ses éditeurs. En option, il peut également être utilisé comme modèle vocal pur, à l’instar de GPT-3.
Sommaire
Un grand modèle de langage qui comprend aussi les images
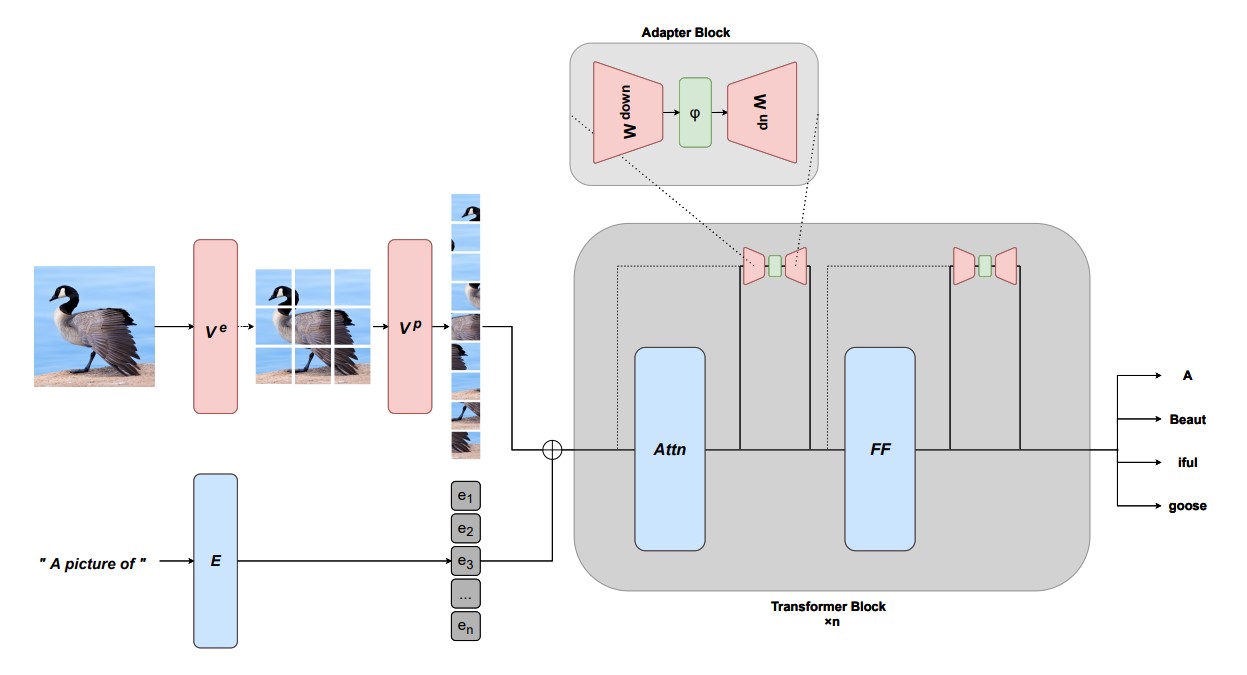
Aleph Alpha a développé une méthode permettant d’étendre les modèles linguistiques générateurs à des modalités supplémentaires, comme la reconnaissance d’images, grâce à un réglage fin basé sur des adaptateurs. MAGMA signifie « Multimodal Augmentation of Generative Models through Adapter-based Finetuning » – il s’agit en fait d’un apprentissage autosurveillé de représentations selon le modèle de transformation de Hugging Face. L’équipe d’Aleph Alpha a utilisé l’approche du « gel » des modèles linguistiques (il s’agit du « Multimodal few-shot learning with frozen language models », en bref : Frozen). Contrairement à Frozen, MAGMA a reçu une série de couches d’adaptateurs supplémentaires et utilise comme encodeur le composant visuel de CLIP (une extension de GPT-3 présentée par OpenAI début 2021, qui conçoit librement des images pour les descriptions de texte).
Un pré-entraînement (pre-training) à grande échelle est de plus en plus considéré comme la norme pour la modélisation de grands modèles de langage de vision (VL). Toutefois, la méthode traditionnelle d’étiquetage des données dans le cadre d’une procédure d’entraînement en plusieurs étapes se heurte à des limites dans le cas des réseaux neuronaux lorsque la taille des modèles augmente. En ce qui concerne la performance, le modèle VL MAGMA aurait marqué des points avec une grande précision, tout en nécessitant une quantité de données échantillonnées nettement plus faible pour l’entraînement que SimVLM (« Simple visual language model pretraining with weak supervision ») – selon l’équipe, MAGMA n’a eu besoin que de 0,2 % de la quantité de données d’exemple utilisée pour SimVLM). Selon une comparaison de référence courante, le modèle VL écrit en Python éclipse probablement aussi son prédécesseur Frozen. Un document de l’équipe Aleph-Alpha publié sur arXiv.org explique le fonctionnement de MAGMA et présente les valeurs comparatives.
(Image : Aleph Alpha)
Télécharger et adapter le modèle multimodal
Si vous souhaitez essayer MAGMA ou l’adapter à vos besoins, vous trouverez le code et les instructions d’installation dans le dépôt GitHub d’Aleph Alpha. PyTorch et Torchvision doivent être installés au préalable, avec la commande pip install -r requirements.txt permet d’installer les autres éléments nécessaires. Les développeurs ont le choix entre les poids pré-entraînés de CLIP (disponibles par défaut) ou ceux de GPT-J. Pour entraîner MAGMA, l’équipe recommande de passer par Deepspeed, en utilisant la commande suivante : deepspeed train.py --config path_to_my_config.
La version open source ouvre, selon son éditeur, la prochaine étape du développement de l’IA après GPT-3. La réponse européenne à GPT-3 pourrait en outre s’établir comme alternative au produit d’OpenAI grâce à ses capacités supplémentaires (multimodalité) et à l’ouverture du code. De plus amples informations sur le modèle sont également disponibles sur le site web d’Aleph Alpha.
Lire aussi
