

{kind=link}
Avec data2vec, une équipe de recherche de Meta/Facebook a annoncé un modèle d’IA qui, outre des tâches visuelles, doit également pouvoir traiter du texte écrit et parlé. Pour les différentes formes d’état (modalities) de l’input, le framework se contente apparemment d’un algorithme commun et d’un mécanisme d’apprentissage uniforme ; les personnes intéressées peuvent consulter le code et des exemples sur GitHub. Selon l’annonce, le nom s’inspire du word2vec développé par Google en 2013, un réseau neuronal spécifique au texte pour la prédiction de clusters de mots avec des voisins de sens. La base du nouveau modèle est la version de base d’un transformateur que l’équipe de chercheurs d’Alexei Baevski avait pré-entraîné pour les données d’images, les données audio vocales et le texte.
Sommaire
La multimodalité apporte la compréhension du contexte aux machines
Les travaux de Google sur DeepMind Perceiver, une version multimodale du Transformer, vont dans le même sens, et l’entreprise allemande Aleph Alpha crée des modèles d’IA multimodaux comme luminous, capables de traiter de manière combinée différents types de données comme l’entrée sous forme de texte et d’image. luminous avait été annoncé fin 2021 lors de l’International Supercomputing Conference, ce dont a rendu compte. Dans le cas de data2vec, l’équipe MetaAI avait, selon son document de recherche, commencé par le pré-entraînement d’un Vision Transformer (ViT), qui était encore spécialement conçu pour des tâches visuelles. Sans autre modification, le même réseau neuronal devrait maintenant maîtriser la reconnaissance vocale et le NLP (Natural Language Processing).
La méthode de prédiction est issue du Self-Supervised Learning et fonctionne par masquage progressif de certaines parties du modèle à entraîner (Masked Prediction). Au cours de plusieurs phases d’entraînement, un modèle apprend à construire les représentations des données d’entrée à l’aide de probabilités. Au cours des étapes suivantes, des parties de l’input sont masquées et le système est ainsi amené à compléter (de manière plus ou moins plausible) les espaces vides (voir fig. 1). L’équipe utilise deux réseaux neuronaux, l’un contenant l’ensemble des données (enseignant), l’autre devant compléter les zones masquées (étudiant).
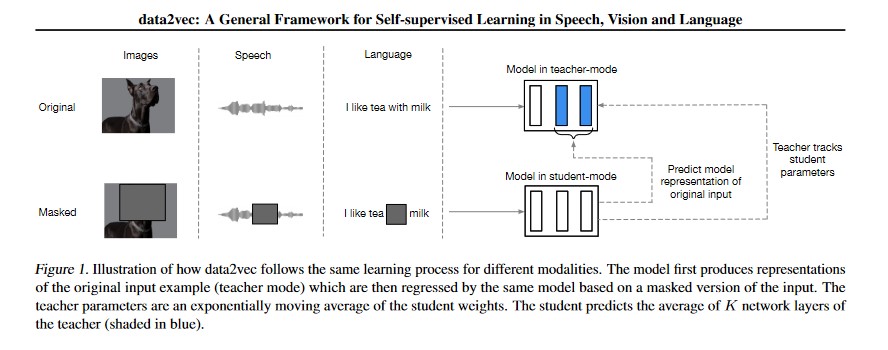
(Image : MetaAI Research)
Ce qui se passe actuellement dans la recherche en IA peut être décrit comme une nouvelle course à l’espace : Aux États-Unis, en Chine et ponctuellement en Europe, des modèles d’IA de plus en plus gigantesques, représentant plusieurs milliards de paramètres, sont créés à intervalles de plus en plus rapprochés et sont entraînés à saisir des ensembles de données non labellisés et à fournir des résultats contextuels. En perspective, il devrait être possible d’utiliser des images, du texte et même du langage parlé de manière combinée, sans avoir besoin de différents programmes. Les machines pourraient ainsi se rapprocher de la « compréhension du monde » et de la « perception du monde », car selon les équipes de recherche impliquées, leur capacité d’apprentissage se rapproche de plus en plus de celle des humains et elles acquièrent elles-mêmes des connaissances contextuelles au-delà de l’entraînement initial – à long terme par l’observation autonome du monde. Cela ouvre la voie à de nombreuses nouvelles applications et à de nouveaux domaines d’activité, qui vont par exemple dans le sens de la réalité augmentée (AR).
Lire aussi

IA générale : petites et grandes étapes sur le chemin
Si, par le passé, les modèles étaient encore des machines spéciales entraînées à des cas d’application clairement délimités, comme par exemple la reconnaissance des piétons dans la circulation routière, l’assistance vocale, la traduction automatique ou les applications à usage unique destinées au traitement de texte pur, le développement va désormais très vite au-delà. Selon les initiés, l’avenir appartient à la multimodalité, c’est-à-dire au traitement de différents types de données et de médias dans une machine. L’entraînement des réseaux neuronaux profonds nécessaires à cet effet se fait de plus en plus sous la forme d’un apprentissage auto-supervisé ou non supervisé.
Entretien sur l’IA : Où va l’Europe ?

Le chemin est jalonné d’étapes plus ou moins importantes, et les hyperscalers américains investissent de manière frappante pour faire avancer le développement dans ce domaine. L’annonce par Mark Zuckerberg d’un Metaverse et du changement de nom de Facebook en Meta avait suscité quelques moqueries sur la toile, car l’aspect ludique de jeu d’ordinateur de sa vidéo marketing ne permet pas de saisir le potentiel de bouleversement social du développement de l’IA. Ce dont il s’agit est plus tangible dans les documents de recherche actuels sur les modèles d’IA les plus récents qui sont en train d’être lancés.
Plongée technique et informations complémentaires
Ceux qui souhaitent en savoir plus sur data2vec trouveront leur bonheur dans le billet de blog de l’équipe de méta-chercheurs d’Alexei Baevski ou pourront consulter le document de recherche fraîchement publié. Les modèles et le code de data2vec sont disponibles sur GitHub. Des informations sur Perceiver sont disponibles sur le blog de DeepMind. Des informations sur la recherche en IA multimodale en cours en Europe peuvent être trouvées dans un article sur le lancement d’OpenGPT-X. La recherche sur l’extension multimodale de modèles génératifs par le biais de l’adaptation (MAGMA), qui est à la base des modèles d’IA utilisés par Aleph Alpha, est désormais également disponible sur arXiv.org.